
Transformar dados em inteligência
Vivemos numa era em que os dados são gerados a uma velocidade nunca vista. Transformar uma enorme quantidade de dados em bruto em informação útil para o apoio à tomada de decisão é um dos maiores desafios das organizações atuais.
Mas como é que os dados nos podem ajudar a tomar decisões informadas de forma rápida e eficiente?
É precisamente neste ponto em que entra o Machine Learning.
De uma forma simplista, o Machine Learning é um campo da inteligência artificial que permite que os computadores consigam aprender a partir dos dados. Em vez de serem programados com regras fixas, os algoritmos de Machine Learning analisam os dados, identificam padrões e evoluem com base na experiência.
O que é que os computadores conseguem aprender?
Com acesso a grandes volumes de dados, um algoritmo de Machine Learning pode descobrir relações entre variáveis, classificar informações, fazer previsões e até tomar decisões. Esta capacidade abre portas para inúmeras aplicações diversas áreas.
Podemos dizer que um projeto de Machine Learning envolve três fases distintas:
- Recolha e preparação de dados: nesta fase inicial, recolhem-se os dados necessários para resolver um certo problema, que são tratados de forma a garantir que têm qualidade suficiente para o nosso modelo. Esta é a primeira e talvez a fase mais crítica para o sucesso de um modelo de Machine Learning.
- Escolha e treino do modelo: após a preparação dos dados, seleciona-se o tipo de modelo de Machine Learning mais adequado ao problema em questão, tendo em consideração os dados disponíveis e o objetivo que pretendemos alcançar. Os dados preparados são utilizados para “ensinar” o modelo, permitindo-lhe identificar padrões e estabelecer relações entre variáveis.
- Avaliação e melhoria do modelo: por fim, o desempenho do modelo é testado com dados que o modelo não teve acesso na fase anterior, a fase de treino. Com base nos resultados destes testes, realizam-se ajustes para otimizar o modelo e garantir melhores resultados.
Este artigo é uma introdução ao vasto mundo de Machine Learning, pelo que vamos começar por falar sobre os principais tipos de Machine Learning – supervised learning e unsupervised learning – explicando o que significa cada um de forma simples.
Aprendizagem Supervisionada
A Aprendizagem Supervisionada (Supervised Learning) é um tipo de Machine Learning em que o algoritmo é treinado com dados rotulados. Ou seja, para cada conjunto de variáveis de entrada, existe um resultado conhecido, a variável target. O objetivo principal destes modelos é aprender a relação entre os dados de entrada e a variável target, de forma a conseguir realizar previsões com precisão.
De forma geral, os modelos supervisionados enquadram-se em duas categorias principais:
- Classificação – O objetivo é prever categorias ou classes (por exemplo, identificar se um e-mail é spam ou não);
- Regressão – O objetivo é prever valores numéricos contínuos (por exemplo, estimar as vendas mensais de um supermercado).
Uma forma simples para entender o processo de aprendizagem supervisionada por parte destes modelos é fazer uma analogia com o processo de aprendizagem dos nomes das frutas por uma criança. Inicialmente, ao ver uma fruta pela primeira vez, a criança não saberá identificá-la. No entanto, após lhe serem apresentadas diferentes frutas com os respetivos nomes por diversas vezes, a criança começa a identificar corretamente cada uma delas. Com mais prática (treino), a criança torna-se capaz de identificar as frutas de forma quase automática. O mesmo acontece com um modelo de Machine Learning supervisionado.
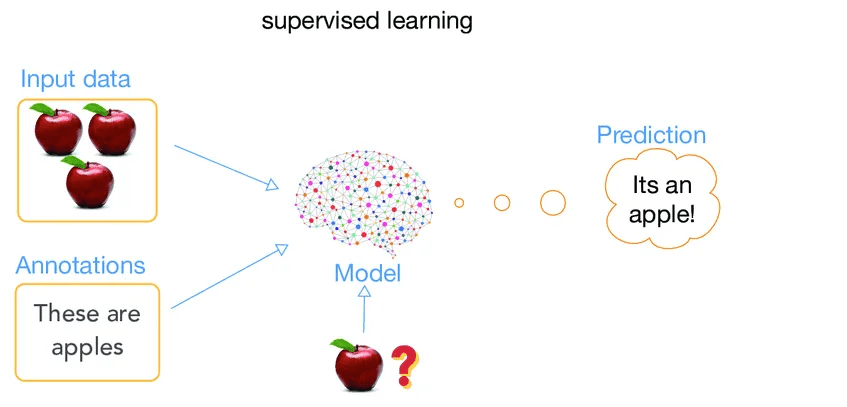
Na prática, é perfeitamente possível construir um modelo de Machine Learning para classificar imagens de frutas. Este processo pode ser dividido nas três fases explicadas na introdução:
Fase 1 – Recolha e preparação dos dados
Devem ser recolhidas diversas imagens de diferentes tipos de frutas. Para garantir que o modelo aprende de forma eficaz, é importante que as imagens sejam captadas sob diferentes condições de iluminação, de vários ângulos e com diferentes variações (tamanho, cor, fundo, etc.). Uma preparação cuidadosa garante que o modelo tenha dados representativos e variados para treinar.
Fase 2 – Escolha e treino do modelo
Nesta fase, escolhe-se um modelo de classificação, uma vez que o objetivo é identificar uma categoria (nome da fruta) com base na imagem. O processo de treino consiste em apresentar as imagens (variáveis de entrada) ao modelo, juntamente com a respetiva classificação correta (variável de saída). No início, o modelo não saberá reconhecer nenhuma fruta, tal como a criança. Mas à medida que vai sendo “treinado” com múltiplos exemplos, começa a perceber padrões e associações (por exemplo, se uma fruta é amarela, tem determinado tamanho e uma ligeira curvatura, provavelmente é uma banana).
Fase 3 – Avaliação e melhoria do modelo
Depois de treinado, o modelo é testado com um novo conjunto de imagens diferentes daquelas usadas durante o treino, de modo a verificar se é capaz de fazer previsões corretas. Se o desempenho for satisfatório, o modelo pode ser considerado como concluído. Caso contrário, poderá ser necessário otimizá-lo, ajustando parâmetros do modelo, utilizando mais imagens ou melhorando a qualidade e diversidade das imagens.
Aprendizagem Não Supervisionada
A Aprendizagem Não Supervisionada (Unsupervised Learning) é um tipo de Machine Learning em que o algoritmo é treinado com dados não rotulados. Ou seja, as variáveis de entrada não têm nenhum resultado conhecido associado. O objetivo deste tipo de modelos é identificar padrões e relações entre as variáveis que não são facilmente identificados por nós.
Ao contrário dos modelos Supervisionados, em vez de aprender a prever um valor conhecido, o modelo tenta descobrir, de forma autónoma, como é que os dados se organizam.
De forma geral, os modelos não supervisionados enquadram-se em duas categorias principais:
- Clustering (agrupamento) – O objetivo é identificar grupos ou segmentos naturais nos dados (por exemplo, agrupar clientes com comportamentos de compra semelhantes);
- Redução de dimensionalidade – O objetivo é simplificar os dados tentando encontrar relações entre variáveis, mantendo as características mais relevantes (por exemplo, eliminar uma variável que pode ser explicada por outras, evitando redundância de informação).
De forma a tornar palpável o conceito de Unsupervised Learning, vamos retomar a analogia da criança e das peças de fruta. Neste caso, vamos imaginar que a criança ainda não sabe o nome de nenhuma fruta e que lhe é dado um saco com maçãs, laranjas e bananas e três cestos vazios. De seguida é pedido à criança que distribua as frutas pelos três cestos, agrupando as do mesmo tipo. É expectável que a criança, mesmo sem saber o nome das frutas, consiga colocar as maçãs num cesto, as laranjas no outro e as bananas no último cesto, agrupando-as com base nas suas semelhanças visuais (cor, tamanho, forma). O modelo de Machine Learning atua de forma semelhante: organiza os dados com base em padrões, sem precisar de instruções explícitas.
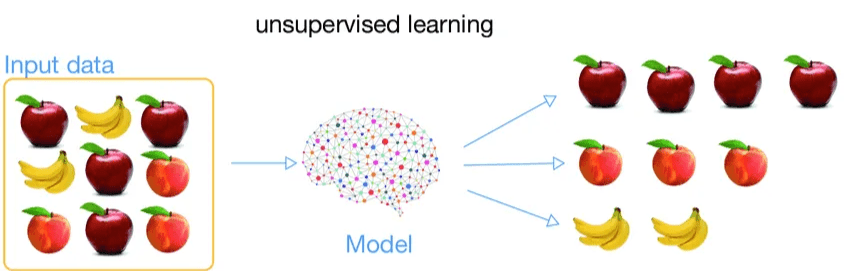
Na prática, também é possível construir um modelo de Machine Learning para agrupar imagens de frutas com base nas suas semelhanças. Este processo pode ser dividido nas três fases explicadas na introdução:
Fase 1 – Recolha e preparação dos dados
Tal como na aprendizagem supervisionada, é necessário recolher um conjunto diversificado de imagens de frutas. No entanto, neste caso, não é necessário rotular as imagens com os nomes das frutas. O foco está em garantir diversidade nos dados (variações de cor, tamanho, formato, iluminação, etc.) para que o modelo tenha boas bases para identificar padrões.
Fase 2 – Escolha e treino do modelo
Escolhe-se agora um modelo de clustering (agrupamento), que irá analisar as imagens e agrupá-las com base em características comuns. Durante o treino, o modelo não recebe nenhuma indicação sobre a forma como deve agrupar as frutas, deixa-se apenas o modelo observar as semelhanças e diferenças entre os dados (por exemplo, é possível que o modelo agrupe todas as frutas amarelas de forma alongada num grupo, que provavelmente corresponde às bananas, mesmo sem saber o nome dessa fruta).
Fase 3 – Avaliação e melhoria do modelo
Após o modelo agrupar as imagens, a avaliação pode ser feita verificando se os grupos formados fazem sentido do nosso ponto de vista (por exemplo, se todas as bananas estão no mesmo grupo). Caso o agrupamento não seja satisfatório, podem ser feitas melhorias como alterar o número de grupos esperados, adicionar mais imagens ou usar outro algoritmo mais adequado à natureza dos dados.
O mais importante… não é o algoritmo
Neste artigo, explorámos os fundamentos de Machine Learning – Aprendizagem Supervisionada e Aprendizagem Não Supervisionada. Enquanto que a Aprendizagem Supervisionada tem como base dados rotulados e objetivos bem definidos (como a classificação ou previsão de valores), a Apredizagem Não Supervisionada procura padrões “escondidos” nos dados, revelando relações que nem sempre são evidentes.
Em ambos os casos, o objetivo é transformar dados em informação útil, um desafio cada vez mais presente nas organizações modernas. No entanto, o sucesso de qualquer projeto nesta área não depende apenas do algoritmo usado, mas, acima de tudo, da qualidade dos dados.





