
Prever o futuro não é opcional
A tomada de decisão suportada por dados deixou de ser um fator diferenciador entre empresas e passou a ser uma necessidade. Num mercado cada vez mais competitivo, a capacidade de antecipar comportamentos, tendências e eventos futuros pode ser o fator chave que dita o sucesso de uma estratégia.
É evidente que devemos aprender com os erros de experiências passadas, evitando repeti-los. Também é inegável que prever os resultados de certas decisões antes de as tomar, apenas com base em dados históricos, representa uma vantagem significativa. No entanto, nós, humanos, temos alguma dificuldade em aprender com os erros do passado, e temos ainda maior dificuldade em prever o futuro, com algum rigor, com base em informações passadas. Isto deve-se, muitas vezes, às inúmeras possibilidades e complexidade das variáveis e da forma como se relacionam entre si. É precisamente neste ponto em que entram os modelos preditivos de Machine Learning.
O que é um modelo preditivo?
Um modelo preditivo, tal como o nome sugere, é um modelo matemático que tem como objetivo prever um resultado (variável target) com base nos dados disponíveis (variáveis de entrada). Para tal, podem ser utilizados modelos supervisionados (em que os modelos são treinados com dados rotulados) e modelos não supervisionados (em que os modelos são treinados com dados não rotulados, sendo responsáveis por encontrar relações entre as variáveis e agrupá-las de forma coerente). Se quiser saber mais sobre modelos supervisionados e não supervisionados, consulte este artigo.
Atualmente, estes modelos são utilizados em diversas indústrias, para múltiplos fins, como para a previsão de vendas, deteção de fraudes, diagnóstico de doenças, entre muitos outros.
Tipos de modelos preditivos
Na maioria das vezes em que se fala em modelos preditivos, fala-se em algoritmos de regressão ou de classificação. Apesar destes serem os mais conhecidos, existem outros modelos que também se enquadram no contexto de antecipação de resultados.
Neste artigo, vamos abordar três dos tipos de modelos preditivos mais conhecidos, com o apoio de exemplos práticos da sua aplicação e gráficos explicativos.
Regressão – Previsão de Valores Contínuos:
Os modelos de regressão são aplicados quando a variável a prever (variável dependente) é numérica e contínua e apresenta uma relação com as variáveis de entrada (variáveis independentes).
Quando essa relação é linear, estamos perante uma regressão linear. Caso esta relação não seja linear (por exemplo, quadrática), estamos perante uma regressão polinomial. Estes são dois dos tipos de regressão mais utilizados.
Exemplo:
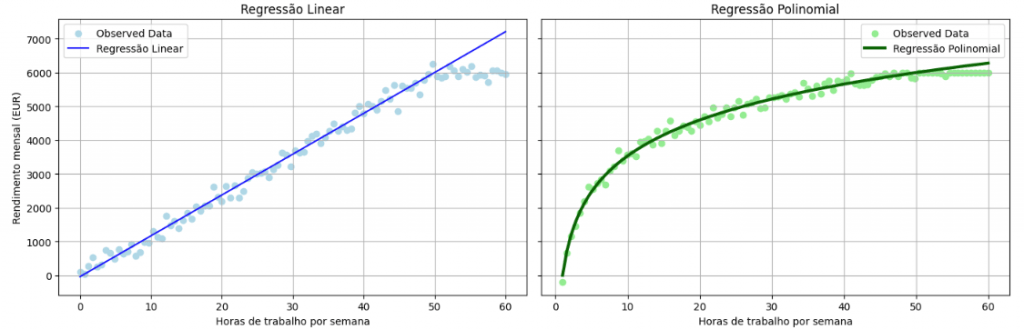
Para ilustrar estes dois tipos de regressão, observe os gráficos seguintes. No gráfico da esquerda temos uma regressão linear, onde existe uma relação constante entre a variável de entrada (horas de trabalho semanais) e a variável dependente (rendimento mensal). No gráfico da direita está representada uma regressão polinomial, onde o aumento do rendimento aumenta com o número de horas até certo ponto, mas tende a estabilizar após as 40 horas de trabalho semanal.
Classificação – Previsão de Categorias Discretas:
Os modelos de classificação são utilizados quando a variável a prever assume valores categóricos (por exemplo: “sim” ou “não”; “compra” ou “não compra”). O objetivo destes modelos é prever a que classe pertence uma nova observação com base nos padrões identificados nas observações anteriores.
A classificação pode ser binária (quando o modelo prevê entre dois possíveis resultados) ou multiclasse (quando existem três ou mais resultados possíveis).
Exemplo:
Um caso clássico onde se aplicam modelos de classificação é na deteção de spam em e-mails.
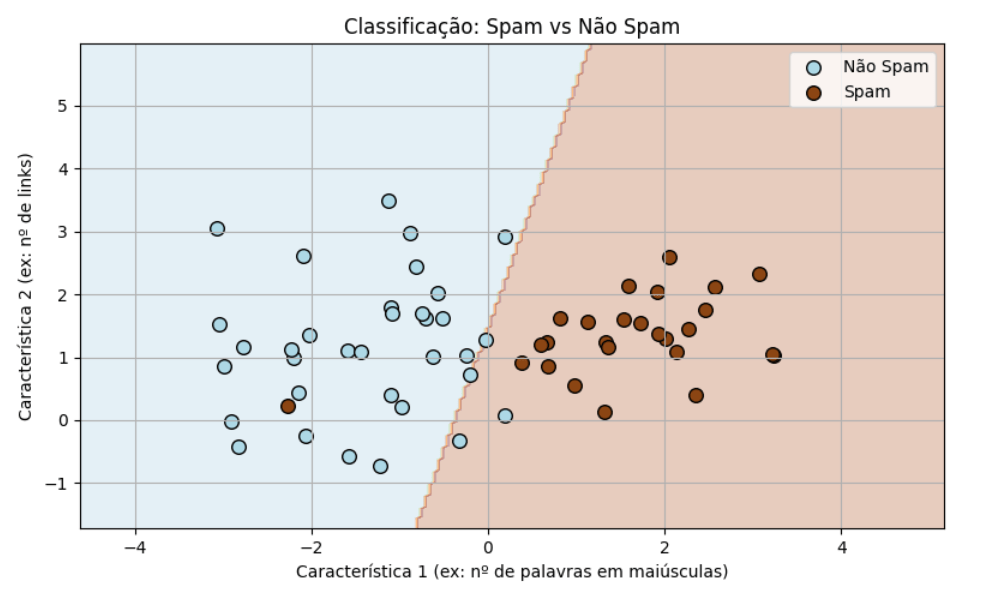
Neste exemplo, o modelo é treinado com exemplos rotulados de e-mails, usando as variáveis “número de palavras em maiúsculas” e “número de links”. Depois de treinado, o modelo “desenha” uma fronteira de decisão, ilustrada no gráfico abaixo, que separa as observações consideradas “spam” das consideradas **“não spam”.
Neste caso, depois de treinado, ao receber um novo e-mail, o modelo irá prever se se trata de spam ou não spam, com base nestas duas variáveis e, consequentemente, na posição desse e-mail no espaço de decisão representado abaixo.
Clustering – Agrupar com base nas semelhanças:
O clustering é utilizado para segmentar observações em grupos (clusters), com base em características comuns entre essas observações. Os clusters são formados de forma a que as observações dentro do mesmo cluster estejam mais próximas entre si do que em relação a observações de outros clusters.
Este agrupamento é especialmente útil porque permite descobrir padrões ou relações desconhecidas, e não evidentes, nos dados.
Exemplo:
Uma loja online, com acesso a dados sobre os seus clientes, aplicou um modelo de clustering com o objetivo de descobrir padrões ou perfis de comportamento, obtendo o seguinte resultado:
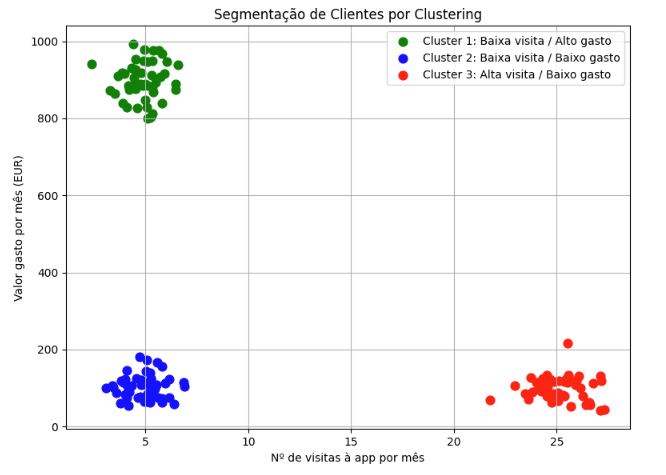
Do gráfico acima podemos concluir que o modelo agrupou os clientes em três diferentes grupos:
- Baixa frequência de visitas e baixo gasto;
- Alta frequência de visitas e baixo gasto;
- Baixa frequência de visitas e alto gasto.
Esta segmentação pode ser utilizada para desenvolver campanhas de marketing personalizadas para cada grupo de clientes, aumentando a eficácia da comunicação e o retorno destas ações.
O poder está nos dados
Seja através da previsão de valores numéricos, da classificação em diferentes categorias ou do agrupamento de observações com características semelhantes, os modelos preditivos são ferramentas poderosas, cuja utilização tem vindo a aumentar entre as empresas que pretendem tirar um melhor partido dos dados que possuem.
O sucesso de qualquer modelo preditivo depende de vários fatores, sendo o principal a qualidade dos dados. Por muito bem construído que um modelo esteja, o seu desempenho nunca será extraordinário se os dados (sejam eles de treino, de teste ou os próprios dados sobre os quais se farão previsões) forem incompletos, desatualizados ou mal estruturados.
Na B2F, ajudamos as organizações a estruturarem os seus dados, a integrarem múltiplas fontes de informação e a manterem bases de dados atualizadas e confiáveis, garantindo assim a base necessária para o sucesso dos seus projetos de Machine Learning.





