
Turning Data into Intelligence
We live in an era where data is being generated at an unprecedented speed. Turning vast amounts of raw data into useful information to support decision-making is one of the greatest challenges faced by today’s organizations.
But how can data help us make informed decisions quickly and efficiently?
This is precisely where Machine Learning comes in.
In simple terms, Machine Learning is a field of artificial intelligence that enables computers to learn from data. Instead of being programmed with fixed rules, Machine Learning algorithms analyze data, identify patterns, and evolve based on experience.
What can computers learn?
With access to large volumes of data, a Machine Learning algorithm can uncover relationships between variables, classify information, make predictions, and even make decisions. This capability opens the door to countless applications across various fields.
We can say that a Machine Learning project involves three distinct phases:
- Data collection and preparation: in this initial phase, the necessary data to solve a specific problem is gathered and processed to ensure it has sufficient quality for our model. This is the first and perhaps the most critical phase for the success of a Machine Learning model.
- Model selection and training: after data preparation, the most suitable type of Machine Learning model is chosen for the problem at hand, considering the available data and the goal we want to achieve. The prepared data is used to “train” the model, enabling it to identify patterns and establish relationships between variables.
- Model evaluation and improvement: finally, the model’s performance is tested with data that the model did not have access to during the previous training phase. Based on the results of these tests, adjustments are made to optimize the model and ensure better outcomes.
This article is an introduction to the vast world of Machine Learning, so we will start by discussing the main types of Machine Learning – supervised learning and unsupervised learning – explaining what each one means in simple terms.
Supervised Learning
Supervised Learning (Supervised Learning) is a type of Machine Learning where the algorithm is trained with labeled data. In other words, for each set of input variables, there is a known outcome, the target variable. basedThe main objective of these models is to learn the relationship between the input data and the target variable. basedso as to be able to make accurate predictions.
In general, supervised models fall into two main categories:
- Classification - The goal is to predict categories or classes (for example, identifying whether an email is spam or not);
- Regression – The goal is to predict continuous numerical values (for example, estimating a supermarket’s monthly sales).
A simple way to understand the supervised learning process of these models is to make an analogy with how a child learns the names of fruits. Initially, when seeing a fruit for the first time, the child won’t know how to identify it. However, after being shown different fruits along with their names several times, the child begins to correctly identify each one. With more practice (training), the child becomes able to identify the fruits almost automatically. The same happens with a supervised Machine Learning model.
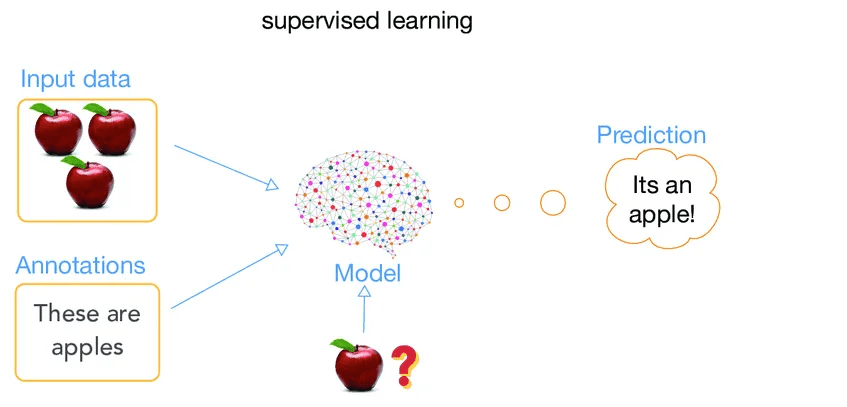
In practice, it is perfectly possible to build a Machine Learning model to classify images of fruits. This process can be divided into the three phases explained in the introduction:
Phase 1 – Data collection and preparation
Various images of different types of fruits should be collected. To ensure the model learns effectively, it is important that the images are captured under different lighting conditions, from various angles, and with different variations (size, color, background, etc.). Careful preparation ensures the model has representative and diverse data to train on.
Phase 2 – Model selection and training
In this phase, a classification model is chosen since the goal is to identify a category (the fruit’s name) based on the image. The training process involves presenting the images (input variables) to the model along with their correct classification (output variable). At first, the model won’t know how to recognize any fruit, just like the child. But as it gets “trained” with multiple examples, it begins to understand patterns and associations (for example, if a fruit is yellow, has a certain size, and a slight curve, it is probably a banana).
Phase 3 – Model evaluation and improvement
After training, the model is tested with a new set of images different from those used during training to verify if it can make accurate predictions. If the performance is satisfactory, the model can be considered complete. Otherwise, it may be necessary to optimize it by adjusting model parameters, using more images, or improving the quality and diversity of the images.
Unsupervised Learning
Unsupervised Learning (Unsupervised Learning) is a type of Machine Learning where the algorithm is trained with unlabeled data. In other words, the input variables have no known associated outcomes. The goal of this type of model is to identify patterns and relationships between variables that are not easily detected by us.
Unlike Supervised models, instead of learning to predict a known value, the model tries to autonomously discover how the data is organized.
In general, unsupervised models fall into two main categories:
- Clustering – The goal is to identify natural groups or segments in the data (for example, grouping customers with similar purchasing behaviors);
- Dimensionality reduction – The goal is to simplify the data by finding relationships between variables while retaining the most relevant features (for example, eliminating a variable that can be explained by others, thus avoiding redundant information).
To make the concept tangible of Unsupervised LearningLet’s revisit the analogy of the child and the pieces of fruit to make the concept of Unsupervised Learning tangible. In this case, imagine the child doesn’t know the names of any fruits and is given a bag containing apples, oranges, and bananas along with three empty baskets. The child is then asked to distribute the fruits into the three baskets, grouping those of the same type. It is expected that the child, even without knowing the names of the fruits, will place the apples in one basket, the oranges in another, and the bananas in the last basket, grouping them based on their visual similarities (color, size, shape). A Machine Learning model works similarly: it organizes data based on patterns without needing explicit instructions.
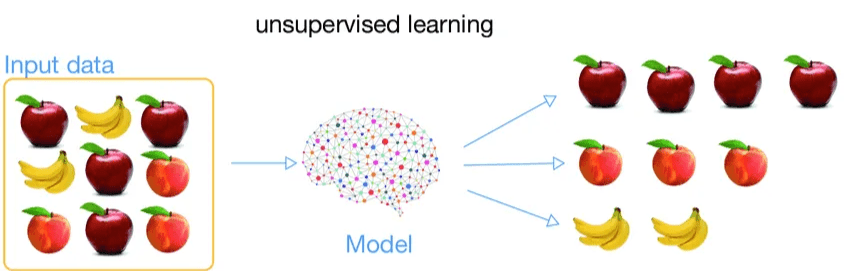
In practice, it is also possible to build a Machine Learning model to cluster images of fruits based on their similarities. This process can be divided into the three phases explained in the introduction:
Phase 1 – Data collection and preparation
Just like in supervised learning, it is necessary to collect a diverse set of fruit images. However, in this case, labeling is not required. the images with the names of the fruits. The focus is on ensuring diversity in the data (variations in color, size, shape, lighting, etc.) so that the model has a solid foundation for identifying patterns.
Phase 2 – Model selection and training
A model is now chosen for clustering (clustering), which will analyze the images and group them based on common characteristics. During training, the model receives no indication of how the fruits should be grouped—it is simply allowed to observe the similarities and differences in the data (for example, the model may group all the long, yellow fruits together, which likely corresponds to bananas, even without knowing the name of the fruit).
Phase 3 – Model evaluation and improvement
After the model groups the images, the evaluation can be done by checking whether the formed groups make sense from our point of view (for example, if all the bananas are in the same group). If the clustering is not satisfactory, improvements can be made, such as changing the expected number of groups, adding more images, or using a different algorithm better suited to the nature of the data.
The most important thing… is not the algorithm
In this article, we explored the fundamentals of Machine Learning – Supervised Learning and Unsupervised LearningWhile Supervised Learning is based on labeled data and well-defined objectives (such as classification or value prediction), Unsupervised Learning seeks “hidden” patterns in the data, revealing relationships that are not always obvious.
In both cases, the goal is to transform data into useful information—a challenge increasingly present in modern organizations. However, the success of any project in this area does not depend solely on the algorithm used, but above all, on the quality of the data.





